

前言
本文以“【欣小萌】芒种,一想到你我就……”为教程视频
![图片[1]-用Python做一个漂亮小姐姐词云跳舞视频-软件开发技术分享](https://upyun.drixn.com/2021/02/20210208135258539-4000x2500.jpg)
下载视频
获取弹幕内容
导入用到的库
import requestsimport pandas as pdimport reimport timeimport randomfrom concurrent.futures import ThreadPoolExecutorimport datetimefrom fake_useragent import UserAgent# 随机产生请求头ua = UserAgent(verify_ssl=False, path='fake_useragent.json')start_time = datetime.datetime.now()import requests import pandas as pd import re import time import random from concurrent.futures import ThreadPoolExecutor import datetime from fake_useragent import UserAgent # 随机产生请求头 ua = UserAgent(verify_ssl=False, path='fake_useragent.json') start_time = datetime.datetime.now()import requests import pandas as pd import re import time import random from concurrent.futures import ThreadPoolExecutor import datetime from fake_useragent import UserAgent # 随机产生请求头 ua = UserAgent(verify_ssl=False, path='fake_useragent.json') start_time = datetime.datetime.now()
爬取弹幕数据
def Grab_barrage(date):# 伪装请求头headers = {"sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-site","accept-encoding": "gzip","origin": "https://www.bilibili.com","referer": "https://www.bilibili.com/video/BV1sJ411P7CF","user-agent": ua.random,"cookie": "chage to your cookies"}# 构造url访问 需要用到的参数 爬取指定日期的弹幕params = {'type': 1,'oid': '116963870','date': date}# 发送请求 获取响应response = requests.get(url, params=params, headers=headers)# print(response.encoding) 重新设置编码response.encoding = 'utf-8'# print(response.text)# 正则匹配提取数据 转成集合去除重复弹幕comment = set(re.findall('<d p=".*?">(.*?)</d>', response.text))# 将每条弹幕数据写入txtwith open('bullet.txt', 'a+') as f:for con in comment:f.write(con + '\n')print(con)time.sleep(random.randint(1, 3)) # 休眠def Grab_barrage(date): # 伪装请求头 headers = { "sec-fetch-dest": "empty", "sec-fetch-mode": "cors", "sec-fetch-site": "same-site", "accept-encoding": "gzip", "origin": "https://www.bilibili.com", "referer": "https://www.bilibili.com/video/BV1sJ411P7CF", "user-agent": ua.random, "cookie": "chage to your cookies" } # 构造url访问 需要用到的参数 爬取指定日期的弹幕 params = { 'type': 1, 'oid': '116963870', 'date': date } # 发送请求 获取响应 response = requests.get(url, params=params, headers=headers) # print(response.encoding) 重新设置编码 response.encoding = 'utf-8' # print(response.text) # 正则匹配提取数据 转成集合去除重复弹幕 comment = set(re.findall('<d p=".*?">(.*?)</d>', response.text)) # 将每条弹幕数据写入txt with open('bullet.txt', 'a+') as f: for con in comment: f.write(con + '\n') print(con) time.sleep(random.randint(1, 3)) # 休眠def Grab_barrage(date): # 伪装请求头 headers = { "sec-fetch-dest": "empty", "sec-fetch-mode": "cors", "sec-fetch-site": "same-site", "accept-encoding": "gzip", "origin": "https://www.bilibili.com", "referer": "https://www.bilibili.com/video/BV1sJ411P7CF", "user-agent": ua.random, "cookie": "chage to your cookies" } # 构造url访问 需要用到的参数 爬取指定日期的弹幕 params = { 'type': 1, 'oid': '116963870', 'date': date } # 发送请求 获取响应 response = requests.get(url, params=params, headers=headers) # print(response.encoding) 重新设置编码 response.encoding = 'utf-8' # print(response.text) # 正则匹配提取数据 转成集合去除重复弹幕 comment = set(re.findall('<d p=".*?">(.*?)</d>', response.text)) # 将每条弹幕数据写入txt with open('bullet.txt', 'a+') as f: for con in comment: f.write(con + '\n') print(con) time.sleep(random.randint(1, 3)) # 休眠
爬取弹幕数据
def main():# 开多线程爬取 提高爬取效率with ThreadPoolExecutor(max_workers=4) as executor:executor.map(Grab_barrage, date_list)# 计算所用时间delta = (datetime.datetime.now() - start_time).total_seconds()print(f'用时:{delta}s -----------> 弹幕数据成功保存到本地txt')def main(): # 开多线程爬取 提高爬取效率 with ThreadPoolExecutor(max_workers=4) as executor: executor.map(Grab_barrage, date_list) # 计算所用时间 delta = (datetime.datetime.now() - start_time).total_seconds() print(f'用时:{delta}s -----------> 弹幕数据成功保存到本地txt')def main(): # 开多线程爬取 提高爬取效率 with ThreadPoolExecutor(max_workers=4) as executor: executor.map(Grab_barrage, date_list) # 计算所用时间 delta = (datetime.datetime.now() - start_time).total_seconds() print(f'用时:{delta}s -----------> 弹幕数据成功保存到本地txt')
主函数调用
if __name__ == '__main__':# 目标urlurl = "https://api.bilibili.com/x/v2/dm/history"start = '20201201'end = '20210128'# 生成时间序列date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]print(date_list)count = 0# 调用主函数main()if __name__ == '__main__': # 目标url url = "https://api.bilibili.com/x/v2/dm/history" start = '20201201' end = '20210128' # 生成时间序列 date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')] print(date_list) count = 0 # 调用主函数 main()if __name__ == '__main__': # 目标url url = "https://api.bilibili.com/x/v2/dm/history" start = '20201201' end = '20210128' # 生成时间序列 date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')] print(date_list) count = 0 # 调用主函数 main()
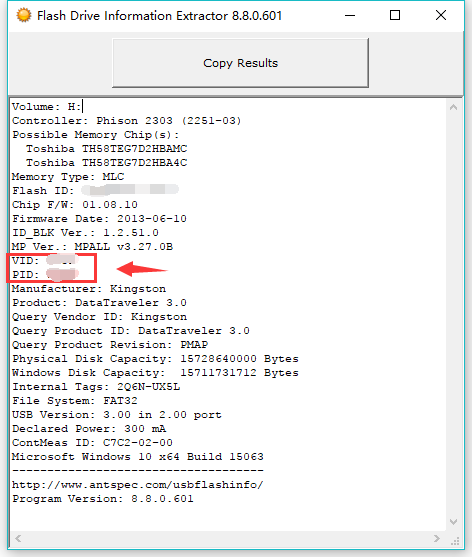
结果如下
![图片[2]-用Python做一个漂亮小姐姐词云跳舞视频-软件开发技术分享](https://upyun.drixn.com/2021/02/20210208030845113.jpg)
从视频中提取图片
import cv2# ============================ 视频处理 分割成一帧帧图片 =======================================cap = cv2.VideoCapture(r"beauty.flv")num = 1while True:# 逐帧读取视频 按顺序保存到本地文件夹ret, frame = cap.read()if ret:if 88 <= num < 888:cv2.imwrite(f"./imgs/img_{num}.jpg", frame) # 保存一帧帧的图片print(f'========== 已成功保存第{num}张图片 ==========')num += 1else:breakcap.release() # 释放资源import cv2 # ============================ 视频处理 分割成一帧帧图片 ======================================= cap = cv2.VideoCapture(r"beauty.flv") num = 1 while True: # 逐帧读取视频 按顺序保存到本地文件夹 ret, frame = cap.read() if ret: if 88 <= num < 888: cv2.imwrite(f"./imgs/img_{num}.jpg", frame) # 保存一帧帧的图片 print(f'========== 已成功保存第{num}张图片 ==========') num += 1 else: break cap.release() # 释放资源import cv2 # ============================ 视频处理 分割成一帧帧图片 ======================================= cap = cv2.VideoCapture(r"beauty.flv") num = 1 while True: # 逐帧读取视频 按顺序保存到本地文件夹 ret, frame = cap.read() if ret: if 88 <= num < 888: cv2.imwrite(f"./imgs/img_{num}.jpg", frame) # 保存一帧帧的图片 print(f'========== 已成功保存第{num}张图片 ==========') num += 1 else: break cap.release() # 释放资源
结果如下
![图片[3]-用Python做一个漂亮小姐姐词云跳舞视频-软件开发技术分享](https://upyun.drixn.com/2021/02/20210207144741515.jpg)
从视频中提取图片
利用百度AI进行人像分割
import cv2import base64import numpy as npimport osfrom aip import AipBodyAnalysisimport timeimport random# 利用百度AI的人像分割服务 转化为二值图 有小姐姐身影的蒙版# 百度云中已创建应用的 APP_ID API_KEY SECRET_KEYAPP_ID = '23649226'API_KEY = '**********************'SECRET_KEY = '**********************'client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)# 保存图像分割后的路径path = './mask_img/'# os.listdir 列出保存到图片名称img_files = os.listdir('./imgs')print(img_files)for num in range(88, len(img_files) + 1):# 按顺序构造出图片路径img = f'./imgs/img_{num}.jpg'img1 = cv2.imread(img)height, width, _ = img1.shape# print(height, width)# 二进制方式读取图片with open(img, 'rb') as fp:img_info = fp.read()# 设置只返回前景 也就是分割出来的人像seg_res = client.bodySeg(img_info)labelmap = base64.b64decode(seg_res['labelmap'])nparr = np.frombuffer(labelmap, np.uint8)labelimg = cv2.imdecode(nparr, 1)labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST)new_img = np.where(labelimg == 1, 255, labelimg)mask_name = path + 'mask_{}.png'.format(num)# 保存分割出来的人像cv2.imwrite(mask_name, new_img)print(f'======== 第{num}张图像分割完成 ========')time.sleep(random.randint(1,2))import cv2 import base64 import numpy as np import os from aip import AipBodyAnalysis import time import random # 利用百度AI的人像分割服务 转化为二值图 有小姐姐身影的蒙版 # 百度云中已创建应用的 APP_ID API_KEY SECRET_KEY APP_ID = '23649226' API_KEY = '**********************' SECRET_KEY = '**********************' client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY) # 保存图像分割后的路径 path = './mask_img/' # os.listdir 列出保存到图片名称 img_files = os.listdir('./imgs') print(img_files) for num in range(88, len(img_files) + 1): # 按顺序构造出图片路径 img = f'./imgs/img_{num}.jpg' img1 = cv2.imread(img) height, width, _ = img1.shape # print(height, width) # 二进制方式读取图片 with open(img, 'rb') as fp: img_info = fp.read() # 设置只返回前景 也就是分割出来的人像 seg_res = client.bodySeg(img_info) labelmap = base64.b64decode(seg_res['labelmap']) nparr = np.frombuffer(labelmap, np.uint8) labelimg = cv2.imdecode(nparr, 1) labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST) new_img = np.where(labelimg == 1, 255, labelimg) mask_name = path + 'mask_{}.png'.format(num) # 保存分割出来的人像 cv2.imwrite(mask_name, new_img) print(f'======== 第{num}张图像分割完成 ========') time.sleep(random.randint(1,2))import cv2 import base64 import numpy as np import os from aip import AipBodyAnalysis import time import random # 利用百度AI的人像分割服务 转化为二值图 有小姐姐身影的蒙版 # 百度云中已创建应用的 APP_ID API_KEY SECRET_KEY APP_ID = '23649226' API_KEY = '**********************' SECRET_KEY = '**********************' client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY) # 保存图像分割后的路径 path = './mask_img/' # os.listdir 列出保存到图片名称 img_files = os.listdir('./imgs') print(img_files) for num in range(88, len(img_files) + 1): # 按顺序构造出图片路径 img = f'./imgs/img_{num}.jpg' img1 = cv2.imread(img) height, width, _ = img1.shape # print(height, width) # 二进制方式读取图片 with open(img, 'rb') as fp: img_info = fp.read() # 设置只返回前景 也就是分割出来的人像 seg_res = client.bodySeg(img_info) labelmap = base64.b64decode(seg_res['labelmap']) nparr = np.frombuffer(labelmap, np.uint8) labelimg = cv2.imdecode(nparr, 1) labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST) new_img = np.where(labelimg == 1, 255, labelimg) mask_name = path + 'mask_{}.png'.format(num) # 保存分割出来的人像 cv2.imwrite(mask_name, new_img) print(f'======== 第{num}张图像分割完成 ========') time.sleep(random.randint(1,2))
结果如下
![图片[4]-用Python做一个漂亮小姐姐词云跳舞视频-软件开发技术分享](https://upyun.drixn.com/2021/02/20210207145412323.jpg)
小姐姐跳舞词云生成
from wordcloud import WordCloudimport collectionsimport jiebaimport refrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as np# 读取数据with open('bullet.txt') as f:data = f.read()# 文本预处理 去除一些无用的字符 只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "/".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data, cut_all=True)result_list = []with open('stop_words.txt', encoding='utf-8') as f:con = f.read().split('\n')stop_words = set()for i in con:stop_words.add(i)for word in seg_list_exact:# 设置停用词并去除单个词if word not in stop_words and len(word) > 1:result_list.append(word)# 筛选后统计词频word_counts = collections.Counter(result_list)path = './wordcloud/'for num in range(88, 888):img = f'./mask_img/mask_{num}'# 获取蒙版图片mask_ = 255 - np.array(Image.open(img))# 绘制词云plt.figure(figsize=(8, 5), dpi=200)my_cloud = WordCloud(background_color='black', # 设置背景颜色 默认是blackmask=mask_, # 自定义蒙版mode='RGBA',max_words=500,font_path='simhei.ttf', # 设置字体 显示中文).generate_from_frequencies(word_counts)# 显示生成的词云图片plt.imshow(my_cloud)# 显示设置词云图中无坐标轴plt.axis('off')word_cloud_name = path + 'wordcloud_{}.png'.format(num)my_cloud.to_file(word_cloud_name) # 保存词云图片print(f'======== 第{num}张词云图生成 ========')from wordcloud import WordCloud import collections import jieba import re from PIL import Image import matplotlib.pyplot as plt import numpy as np # 读取数据 with open('bullet.txt') as f: data = f.read() # 文本预处理 去除一些无用的字符 只提取出中文出来 new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S) new_data = "/".join(new_data) # 文本分词 seg_list_exact = jieba.cut(new_data, cut_all=True) result_list = [] with open('stop_words.txt', encoding='utf-8') as f: con = f.read().split('\n') stop_words = set() for i in con: stop_words.add(i) for word in seg_list_exact: # 设置停用词并去除单个词 if word not in stop_words and len(word) > 1: result_list.append(word) # 筛选后统计词频 word_counts = collections.Counter(result_list) path = './wordcloud/' for num in range(88, 888): img = f'./mask_img/mask_{num}' # 获取蒙版图片 mask_ = 255 - np.array(Image.open(img)) # 绘制词云 plt.figure(figsize=(8, 5), dpi=200) my_cloud = WordCloud( background_color='black', # 设置背景颜色 默认是black mask=mask_, # 自定义蒙版 mode='RGBA', max_words=500, font_path='simhei.ttf', # 设置字体 显示中文 ).generate_from_frequencies(word_counts) # 显示生成的词云图片 plt.imshow(my_cloud) # 显示设置词云图中无坐标轴 plt.axis('off') word_cloud_name = path + 'wordcloud_{}.png'.format(num) my_cloud.to_file(word_cloud_name) # 保存词云图片 print(f'======== 第{num}张词云图生成 ========')from wordcloud import WordCloud import collections import jieba import re from PIL import Image import matplotlib.pyplot as plt import numpy as np # 读取数据 with open('bullet.txt') as f: data = f.read() # 文本预处理 去除一些无用的字符 只提取出中文出来 new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S) new_data = "/".join(new_data) # 文本分词 seg_list_exact = jieba.cut(new_data, cut_all=True) result_list = [] with open('stop_words.txt', encoding='utf-8') as f: con = f.read().split('\n') stop_words = set() for i in con: stop_words.add(i) for word in seg_list_exact: # 设置停用词并去除单个词 if word not in stop_words and len(word) > 1: result_list.append(word) # 筛选后统计词频 word_counts = collections.Counter(result_list) path = './wordcloud/' for num in range(88, 888): img = f'./mask_img/mask_{num}' # 获取蒙版图片 mask_ = 255 - np.array(Image.open(img)) # 绘制词云 plt.figure(figsize=(8, 5), dpi=200) my_cloud = WordCloud( background_color='black', # 设置背景颜色 默认是black mask=mask_, # 自定义蒙版 mode='RGBA', max_words=500, font_path='simhei.ttf', # 设置字体 显示中文 ).generate_from_frequencies(word_counts) # 显示生成的词云图片 plt.imshow(my_cloud) # 显示设置词云图中无坐标轴 plt.axis('off') word_cloud_name = path + 'wordcloud_{}.png'.format(num) my_cloud.to_file(word_cloud_name) # 保存词云图片 print(f'======== 第{num}张词云图生成 ========')
结果如下
![图片[5]-用Python做一个漂亮小姐姐词云跳舞视频-软件开发技术分享](https://upyun.drixn.com/2021/02/20210208024310592.jpg)
合成跳舞视频
import cv2import os# 输出视频的保存路径video_dir = 'result.mp4'# 帧率fps = 30# 图片尺寸img_size = (1920, 1080)fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)img_files = os.listdir('./wordcloud')for i in range(88, 888):img_path = './wordcloud/' + 'wordcloud_{}.png'.format(i)frame = cv2.imread(img_path)frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同videoWriter.write(frame) # 写进视频里print(f'======== 按照视频顺序第{i}张图片合进视频 ========')videoWriter.release() # 释放资源import cv2 import os # 输出视频的保存路径 video_dir = 'result.mp4' # 帧率 fps = 30 # 图片尺寸 img_size = (1920, 1080) fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放 videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size) img_files = os.listdir('./wordcloud') for i in range(88, 888): img_path = './wordcloud/' + 'wordcloud_{}.png'.format(i) frame = cv2.imread(img_path) frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同 videoWriter.write(frame) # 写进视频里 print(f'======== 按照视频顺序第{i}张图片合进视频 ========') videoWriter.release() # 释放资源import cv2 import os # 输出视频的保存路径 video_dir = 'result.mp4' # 帧率 fps = 30 # 图片尺寸 img_size = (1920, 1080) fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放 videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size) img_files = os.listdir('./wordcloud') for i in range(88, 888): img_path = './wordcloud/' + 'wordcloud_{}.png'.format(i) frame = cv2.imread(img_path) frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同 videoWriter.write(frame) # 写进视频里 print(f'======== 按照视频顺序第{i}张图片合进视频 ========') videoWriter.release() # 释放资源
效果如下
视频插入音频
import moviepy.editor as mpy# 读取词云视频my_clip = mpy.VideoFileClip('result.mp4')# 截取背景音乐audio_background = mpy.AudioFileClip('song.mp4').subclip(17, 44)audio_background.write_audiofile('vmt.mp3')# 视频中插入音频final_clip = my_clip.set_audio(audio_background)# 保存为最终的视频 动听的音乐!漂亮小姐姐词云跳舞视频!final_clip.write_videofile('final_video.mp4')import moviepy.editor as mpy # 读取词云视频 my_clip = mpy.VideoFileClip('result.mp4') # 截取背景音乐 audio_background = mpy.AudioFileClip('song.mp4').subclip(17, 44) audio_background.write_audiofile('vmt.mp3') # 视频中插入音频 final_clip = my_clip.set_audio(audio_background) # 保存为最终的视频 动听的音乐!漂亮小姐姐词云跳舞视频! final_clip.write_videofile('final_video.mp4')import moviepy.editor as mpy # 读取词云视频 my_clip = mpy.VideoFileClip('result.mp4') # 截取背景音乐 audio_background = mpy.AudioFileClip('song.mp4').subclip(17, 44) audio_background.write_audiofile('vmt.mp3') # 视频中插入音频 final_clip = my_clip.set_audio(audio_background) # 保存为最终的视频 动听的音乐!漂亮小姐姐词云跳舞视频! final_clip.write_videofile('final_video.mp4')
效果如下
视频播放器
00:00
00:00
本文参考 叶庭云利用Python做一个漂亮小姐姐词云跳舞视频
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







- 最新
- 最热
只看作者